10 Mar 2026
Широко распространено заблуждение, будто мифы, легенды и сказки утратили свою силу в современном мире. Трудно представить себе что-либо более далёкое от истины. Я сейчас говорю даже не о замаскированных мифах вроде веры в прогресс, хотя в пользу этого примера тоже можно привести убедительные доводы. Я имею в виду мифы и легенды в привычном смысле слова — красочные истории о чудесах, которые мы даём детям и подросткам или оставляем тем взрослым, из которых не успели выбить вкус к чудесному, — тот род историй, которые все, по крайней мере публично, с лёгкостью называют чистым вымыслом.
 Большинство людей в то время считали это чистейшей макулатурой.
Большинство людей в то время считали это чистейшей макулатурой.
Чего большинство людей не замечает — так это того, что истории, которые никто не воспринимает всерьёз, исподволь определяют мир для тех, кто усвоил их в детстве или дорожит ими во взрослом возрасте. Именно потому, что никто не относится к ним серьёзно как к моделям реальности, они проскальзывают через барьеры ментальной цензуры и делают своё дело. Посмотрите, как научная фантастика — низкопробное чтиво для гиковатых подростков по всей Америке и Европе в 1920–1930-х годах — в итоге определила то будущее, которого до сих пор ожидает большинство людей в западном мире, несмотря на каскад разочарований, который потопил бы любое сугубо рациональное мнение на эту тему.
Более того, я неоднократно подробно писал о том, как клише из франшизы «Звёздных войн» и обширного легендариума Толкина исказили мышление привилегированных классов западного мира, поспособствовав, среди прочего, катастрофе, разворачивающейся в момент написания этих строк на восточных равнинах Украины. Воспитайте детей на историях, настаивающих на том, что если вы уверены в своей принадлежности к «хорошим людям», всё непременно обернётся в вашу пользу, — и та ошеломляющая наивность, которая направляет внешнюю политику США и НАТО, следует за этим так же неизбежно, как ночь за днём.
Те, кто с благоговением слушал премьеры четырёх опер «Кольца нибелунга», не выросли на таких историях. Впрочем, как и сам Рихард Вагнер. Их юношеское воображение было сформировано романтическим движением в европейском искусстве и литературе, с его восторженным возрождением средневековой и ренессансной культуры. Знали ли вы, что в разгар предшествующего движения классицизма пьесы Шекспира считались вульгарной дешёвкой?
Их среди прочего вернули в моду романитики, и как раз вовремя, чтобы юный Вагнер был сражён ими наповал. (Ироничный пассаж в его автобиографии описывает детскую попытку написать шекспировскую трагедию; он убил так много персонажей в ранних актах, что ему пришлось вернуть целую вереницу из них в виде призраков в пятом акте, чтобы в конце иметь возможность свести сюжет.)
Со своей тягой к страстям, энтузиазму и непостижимым разуму доводам сердца, романтическое движение было необходимым противовесом классическому культу бескровного разума, и там, где оно преуспело, оно добилось многого. Однако не всё, что романтики пытались осуществить, работало хорошо, и вот здесь мы начнём нашу попытку разобраться в политическом и экономическом подтексте вагнеровских опер.
 Замечали, как много несостоявшихся политических реформаторов хранят в голове именно этот образ — одинокий провидец, героически позирующий на фоне неба?
Замечали, как много несостоявшихся политических реформаторов хранят в голове именно этот образ — одинокий провидец, героически позирующий на фоне неба?
Да, романтическая политика и романтическая экономика существуют. Более того, те из моих читателей, у кого сохранились хоть малейшие воспоминания о контркультуре 1960-х, уже знают об этом гораздо больше, чем им кажется. Чтобы провести связь между вагнеровской оперой, с одной стороны, и бусами, длинными волосами и рок-музыкой — с другой, нам придётся забраться очень далеко назад во времени и поговорить об Иоахиме Флорском.
Иоахим был итальянским монахом, жившим в XII веке, и он стал одним из самых влиятельных мистиков Средневековья. Он проводил много времени в экстатических состояниях общения с Богом и ангелами и уверился, что эти переживания дали ему ключ к тому, как повествование Книги Откровения разворачивалось в современной ему истории.
С точки зрения Иоахима, вся мировая история делилась на три эпохи: Эпоху Отца, продолжавшуюся от сотворения мира до рождения Иисуса; Эпоху Сына, длившуюся оттуда до 1260 года; и Эпоху Святого Духа, которая должна была продолжаться с этого момента до конца света. В грядущую эпоху Святого Духа, учил он, дух любви и согласия разрешит все конфликты между людьми. Католическая церковь отомрёт, потому что её иерархия станет ненужной, а свобода, руководимая любовью, заменит власть закона.
Это было далеко не единственное его пророчество. Когда король Ричард Львиное Сердце направлялся в Третий крестовый поход, он нашёл время заехать в монастырь Иоахима, чтобы попросить мистика предсказать исход его предприятия. Иоахим заверил короля, что крестовый поход быстро сокрушит армии Саладина и вернёт Иерусалим под христианское правление. Он, разумеется, оказался совершенно неправ. Большинству его прочих предсказаний повезло не больше. Иными словами, Иоахим будучи глубоким мистиком, пророком был никудышным.
Высказывания Иоахима о будущем католической церкви и его убеждённость в том, что Антихристом станет папа, не слишком расположили к нему Ватикан. Его идеи были должным образом осуждены как еретические на нескольких церковных соборах. Это лишь гарантировало их популярность среди христианских радикалов и они были подхвачены последующими движениями, которые сегодня помнят только историки-медиевисты — амальрикианцами, дольчинистами и прежде всего Братьями Свободного Духа, которые верили, что эпоха Святого Духа наступила, что человечество освобождено от греха и возвращено к условиям Эдемского сада, и которые изобрели большую часть хипповского образа жизни на семь столетий раньше.
 Быть ребёнком в ту эпоху было очень странно.
Быть ребёнком в ту эпоху было очень странно.
Все эти идеи пустили глубокие корни в европейской культуре. Позже они перемешались с народными сказаниями о стране Кокань — ещё одной забытой, но вездесущей темой европейской культуры и её заморских отпрысков. Американцы, выросшие примерно в одно время со мной, помнят, как Берл Айвс пел «The Big Rock Candy Mountain» — песню о бродяжьем рае, где растут сигаретные деревья и бьют лимонадные ключи, у всех полицейских деревянные ноги, у всех бульдогов — резиновые зубы, а «того, кто выдумал работу, повесили». Да, когда я был мальчишкой, детям позволяли слушать такие песни.
Страна Кокань была именно такам местом. В Кокани жареные поросята расхаживают по пейзажу с ножами в спинах, приглашая вас отрезать кусочек, вино и пиво бьют из родников, а хлебные буханки растут на деревьях. В Кокани никому не нужно работать, потому что всё желаемое само идёт в руки, и единственная трудность, с которой вы сталкиваетесь, — это съесть достаточно, чтобы бедные жареные поросята не бродили вокруг с чувством, что их никто не ценит, потому что никто до сих пор ими не пообедал. В эпохи, когда бедность была повсеместной, а голод — регулярным явлением, такие истории были популярны.
Перенесёмся в XVII век. К тому времени хватка христианства над коллективным воображением Западной Европы ослабевала — наступал Век Разума нашей цивилизации, — и старые мечты начали принимать светские формы. Диггеры, левеллеры, люди Пятой монархии и другие радикалы эпохи Английской гражданской войны были на острие этого процесса. Некоторые из них отнеслись к процессу секуляризации серьёзно и попытались выработать картины будущего, которые чтобы быть правдоподобными не нуждающались в божественном вмешательстве. Именно отсюда мы получили такие странные идеи, как выборы, на которых может голосовать каждый взрослый гражданин, гражданские права, распространяющиеся даже на бедных, и законы, применяемые против богатых, а также конец аристократической монополии на недвижимость, дабы каждая семья могла владеть собственным домом и фермой.
 Наш старый знакомый Шарль Фурье, изобретатель социализма.
Наш старый знакомый Шарль Фурье, изобретатель социализма.
Однако старые утопические мечты о грядущей эпохе, когда мир, братство и изобилие явятся сами собой, никуда не делись. Какое-то время они оставались достоянием тех, кто ещё серьёзно относился к христианству. Это изменилось с приходом романтизма и великого пионера романтической политики и экономики — эксцентричного французского теоретика Шарля Фурье.
Я уже неоднократно писал о Фурье в этих эссе, и не без причины. Хотя большинство наших нынешних радикалов и реформаторов о нём не слышали, а многие из тех, кто слышал, старательно обходят стороной более причудливые аспекты его мысли, Фурье остаётся путеводным духом радикальных традиций западного мира. Продеритесь сквозь его рассуждения о лимонадных океанах и ласковых анти-львах, и вы обнаружите фундаментальный принцип, лежащий в основе всей истории прогрессивного крыла западной политической и экономической мысли: утверждение, что человеческая природа настолько полностью определяется институтами, в которых мы живём, что изменение этих институтов неизбежно повлечёт за собой изменение человеческой природы.
Давайте возьмём марксизм в качестве примера, поскольку куда же без него. Одна из фундаментальных предпосылок марксистской мысли состоит в том, что эгоистическая борьба за богатство, господствующая в капиталистических и докапиталистических обществах — вплоть до самых первых дней после первобытного коммунизма, — является следствием социальных институтов, закрепляющих принцип частной собственности. До того, как этот принцип занял центральное место в общественной жизни, жадность и эгоизм, управляющие современной жизнью, не существовали, — так долго и подробно доказывали марксистские теоретики. Это одно из ключевых теоретических обоснований тезиса о том, что как только социализм сменит капитализм, люди станут от природы склонны к сотрудничеству и щедрости, отдавая свой труд на общее благо, дабы каждый мог получить то, в чём нуждается.
Это, в свою очередь, и есть фундаментальный порок марксизма на практике, потому что предсказанная перемена в человеческой природе все никак не наступает. Марксисты у власти перепробовали все мыслимые способы её вызвать, вплоть до попытки уничтожить всех, кому было больше десяти лет на момент революции, — чтобы пагубное влияние капиталистического общества было искоренено раз и навсегда. Именно такой стратегии придерживался Пол Пот в Камбодже.
 Марксистские режимы неизменно приходят к этому. Так или иначе, именно это обычно случается, когда вы ожидаете, что мир будет соответствовать какой-нибудь произвольной идеологии.
Марксистские режимы неизменно приходят к этому. Так или иначе, именно это обычно случается, когда вы ожидаете, что мир будет соответствовать какой-нибудь произвольной идеологии.
Не сработало. И никогда не сработает. Я пришёл к убеждению, что именно в этом причина того, что столь многие марксистские режимы превращаются в жестокие тирании. Дело не в том, что они или их лидеры от природы злы, а в том, что люди, которыми они правят, просто отказываются вести себя так, как предписывает марксистская теория, — что бы там ни предпринималось. В конце концов когнитивный диссонанс достигает такого предела, что партийные лидеры полностью теряют самообладание и начинают кричать от чистого отчаяния, и очень скоро людей тысячами гонят в трудовые лагеря, а от них к братским могилам.
Та же проблема поражает и другие радикальные политические и экономические схемы, следовавшие по стопам Фурье к берегам лимонадных океанов его мечты. Конечно, есть исключения. Например, рабочие кооперативы работают чрезвычайно хорошо — и, пожалуй, даже лучше, чем их капиталистические конкуренты, поскольку никто не обескровливает бизнес, снимая огромные суммы сливок с верхушки. Некоторые другие ответвления прогрессивного движения тоже способны работать на практике, как я обсуждал в одном из предыдущих постов.
Ключевое, что нужно здесь помнить, — ни одна из работающих систем не ожидает изменения человеческой природы. Все они исходят из того, что при новой системе люди будут столь же жадными, эгоистичными и ленивыми, как и прежде. Работники рабочего кооператива, например, знают, что каждый год будут получать долю прибыли кооператива, и потому имеют самый вульгарно-корыстный мотив, какой только можно вообразить, чтобы работать усердно и поддерживать бесперебойный ход конвейера. Другие работающие системы обеспечивают стимулы того же рода, и потому им не приходится прибегать к жестоким методам, к которым в итоге вынуждены обращаться марксистские режимы.
Всё это было уже заложено в основу, как только теории Фурье стали шаблоном прогрессивной политики по всему западному миру. Однако чтобы разобраться в их воздействии на оперы Вагнера, необходимо помнить, что в его время большая часть этого ещё не была очевидна. Сам фурьеризм уже был испробован — и с треском провалился: из сотен фурьеристских фаланстеров (его термин для коммуны), основанных в различных уголках Европы и обеих Америк, ни один не просуществовал более пары лет, потому что утверждение Фурье о том, что труд, направляемый страстным влечением, будет в четыре раза продуктивнее обычного, попросту не подтвердилось. Радикалы вагнеровской эпохи восприняли это как свидетельство того, что в теориях Фурье есть какой-то изъян, но не отвергли более широкий тезис о том, что изменение институтов способно превратить мир в утопию их мечты.
 Если вы думаете, что Средневековье выглядело так, вам стоит подумать ещё раз.
Если вы думаете, что Средневековье выглядело так, вам стоит подумать ещё раз.
Именно тогда столкнулась романтическая политика и романтический культ Средневековья — с катастрофическими последствиями.
Как мы видели двумя неделями ранее, классическое движение в западном обществе боготворило греко-римскую древность, переосмысляя её как утопию совершенного разума и самообладания, которую ни Платон, ни Цицерон, ни любой другой древний грек или римлянин никогда бы узнали. Романтическое движение ответило тем, что проделало ровно то же самое со Средневековьем, создав воображаемый мир крепких крестьян, распевающих за работой, доблестных рыцарей, обожающе взирающих на своих прекрасных дам, и так далее — через весь обширный набор средневековых клише. Всё это может быть продуктивно, если применять к искусству и литературе. Менее полезно это оказывается в приложении к политике и экономике — и особенно если делать это так, как делали многие европейские радикалы в те времена, когда Вагнер был молод, полон энтузиазма и захвачен политикой своего времени.
В маленьких немецкоязычных странах Центральной Европы недостатка в аристократах не было. У каждого крохотного государства был собственный королевский или герцогский двор, с франкоязычными придворными в нарядных и дорогих костюмах, болтавшими о последних книгах из Парижа и последней музыке из Вены, и все остальные прекрасно понимали, что эти персоны — очень дорогая и бесполезная роскошь, от которой можно было бы спокойно избавиться. Идеалом радикалов тех дней были те самые крепкие крестьяне, распевающие за работой, с их традициями местного самоуправления.
Так распространилась идея о том, что стоит лишь избавиться от надстройки государства — и крестьянский мир их воображения тут же восстановится сам собой, и все заживут долго и счастливо. Это была центральная теория анархизма, как её продвигали близкий друг Вагнера Михаил Бакунин и великое множество других. Они надеялись, что если государство удастся разрушить, общество органически самоорганизуется по образцу средневековых крестьянских общин из романтической грёзы. Им, по всей видимости, никогда не приходило в голову, что государство, которое они презирали, столь же органически самоорганизовалось из тех самых общин раннесредневековой эпохи, которые они превозносили, и что его разрушение просто запустит цикл заново.
 Уильям Моррис. Блестящий художник и писатель; как политический теоретик — не слишком убедительный.
Уильям Моррис. Блестящий художник и писатель; как политический теоретик — не слишком убедительный.
Этот вид романтического социализма можно увидеть в его естественной среде обитания в прекрасном утопическом романе Уильяма Морриса «Вести ниоткуда». Моррис жил примерно в тоже время что и Вагнер и в своём роде обладал столь же впечатляющими творческими дарованиями, и черпал своё вдохновение из того же возрождения германских мифов и легенд, как и Вагнер. (Среди прочего, он совместно с исландским учёным выполнил первый английский перевод «Саги о Вёльсунгах».) Моррисовский идеал социалистической утопии зелен и буколичен, и Средневековье, каким он его себе представлял, выглядывает из-за каждого куста и кустарника.
Отсюда же берёт своё начало и мечта о возврате к земле, которая сыграла столь важную роль на закате контркультуры 1960-х. У Соединённых Штатов никогда не было собственного средневекового крестьянства, поэтому на эту роль были призваны аппалачские горцы; вот почему у стольких хиппи на книжной полке стояла «The Foxfire Book», а на крюке на стене висел горный дульсимер. Вот почему архиромантик и страстный медиевист Толкин играл столь колоссальную роль в представлении контркультуры. Если смотреть шире, американская контркультура 1960-х годов была, по сути, безнадёжно неоригинальной копией европейской контркультуры 1840-х. Музыка была другой, и наркотики тоже — алкоголь и опиум играли в последней примерно ту же роль, что каннабис и ЛСД в первой, — но дух был тот же, как и последствия.
В 1848 и 1849 годах европейские радикалы сумели осуществить те самые стихийные, радостные революции, которые радикалам 1968-го так и не удались. Будучи, однако, романтиками, глубоко пропитанными анархизмом, европейские революционеры не составили никаких планов по удержанию власти после того, как захватили её. Совершив всё, что считали необходимым, они принялись ждать, пока утопия явится путём стихийной самоорганизации.
 Всё, казалось, шло прекрасно, пока не появились солдаты. (Парень с камнем в верхнем левом углу вот-вот превратится из революционного героя в революционного мученика.)
Всё, казалось, шло прекрасно, пока не появились солдаты. (Парень с камнем в верхнем левом углу вот-вот превратится из революционного героя в революционного мученика.)
Вместо утопии явились силы реакции. По всем немецким землям мелкие короли и великие герцоги ненадолго отступили к укреплённым пунктам за пределами городских центров, собрали свои силы и вернулись к власти, без особого труда смахнув баррикады и революционеров. Это более драматичная и насильственная версия того, что произошло после 1968-го года, когда хипповская контркультура схлопнулась сама в себя, и большинство её участников постепенно вернулись к «обывательским» работам и образу жизни, от которых, как они утверждали, отказались навсегда.
Ставки в 1849-м были выше, как и расплата за поражение. Когда революционное движение в маленьком Саксонском королевстве рухнуло, Рихард Вагнер — один из лидеров восстания — бежал из страны с ценой назначенной за его голову. Как и многие другие революционеры того времени, он нашёл убежище в Швейцарии и провёл там годы, живя в бедности, сочиняя эссе и создавая музыку для авангардных опер, которые никто не хотел ставить. Он также много читал философию. Но прежде чем мы сможем осмыслить, куда это его привело, нам придётся поговорить о философии — и ещё об одном совершенно забытом движении, которое остаётся живым, но непризнанным в современных культурах Запада.
Оригинал статьи: The Nibelung’s Ring: The Politics
09 Mar 2026
В конце предыдущего захватывающего этапа нашего путешествия по оперному циклу Рихарда Вагнера «Кольцо нибелунга» мы узнали, как барды и менестрели всего европейского мира, от Исландии до Австрии, добывали свой хлеб и развлекали своих покровителей, пересказывая предания о волшебном золотом кладе, добытом Зигфридом, сразившим ужасного змея Фафнира, — с участием воительницы Брюнхильды, обречённого короля Гунтера и его хладнокровного, дерзкого и зловещего брата Хагена. Это была великолепная коллекция преданий, и она прекрасно удовлетворяла вкусам средневековой публики. А потом — ну, как однажды написал один третьеклассник на контрольной по истории, — потом что-то случилось.
Самым важным из этих «каких-то там событий» стало мероприятие под названием Ренессанс. На протяжении всего Средневековья люди в Европе хоть смутно и осознавали, что до них существовала некая другая цивилизация, но по-настоящему никто не понимал, насколько та цивилизация была иной. Покопайтесь в средневековой литературе и вы найдёте живые пересказы Троянской войны, в которых Ахиллес, Гектор и все остальные изображены рыцарями, сражающимися на турнире у стен средневекового французского города, который по совершенно случайному стечению обстоятельств назывался Троей.
 Так в Средневековье представляли Троянскую войну.
Так в Средневековье представляли Троянскую войну.
Культура Европы в Средние века, безусловно, находилась под сильнейшим влиянием древнегреческой и древнеримской культур. Речь шла не только о том, что каждый образованный человек читал и говорил на латыни, а уцелевшие фрагменты латинской литературы служили основой книжной культуры; как метко заметил К. С. Льюис в «Отброшенном образе», вся картина мира средневековой Европы была заимствована из римских источников. И всё же никто в то время не представлял, сколько штрихов было незаметно внесено в эту картину на протяжении столетий, и насколько древний мир превосходил средневековую Европу в техническом и политическом отношении. Ситуация начала меняться в Италии в XIV веке, когда итальянские интеллектуалы стали уделять больше внимания античной литературе, чем христианской теологии.
Это был потрясающий опыт. Представьте, дорогой читатель, что завтра в новостях вдруг расскажут о том, что археологи в ходе серии раскопок в Африке обнаружили неопровержимые доказательства существования глобальной цивилизации, десять тысяч лет назад уже достигшей уровня, которого мы сами пока не достигли. Представьте, что все новые и новые раскопки дадут всё новые подтверждения этому, неопровержимо демонстрируя, что современная индустриальная цивилизация на самом деле весьма примитивна по сравнению с могучей цивилизацией, существовавшей в последние тысячелетия ледникового периода. Подумайте, какой удар это нанесло бы по нашему самолюбию и нашему самоощущению «передового отряда человечества». Примерно это и пережила Европа, когда достижения Греции и Рима наконец-то достигли коллективного воображения западного мира.
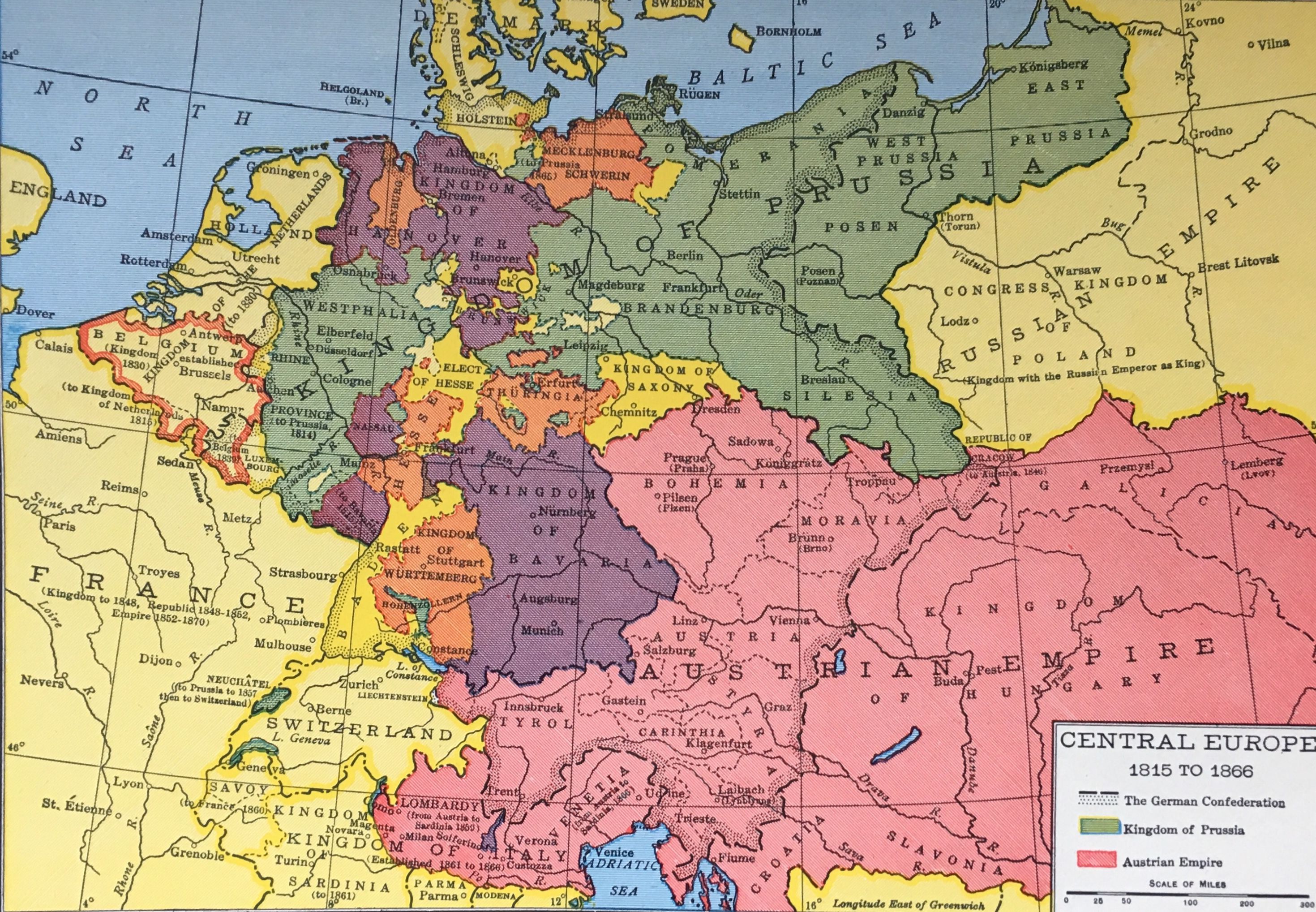 Германия, когда Вагнер был мальчиком. Каждое из этих цветных пятнышек — независимое государство.
Германия, когда Вагнер был мальчиком. Каждое из этих цветных пятнышек — независимое государство.
Нигде этот удар не был ощутимее, чем в мозаике маленьких стран, простиравшейся от долины Рейна до долины Дуная, где наиболее распространёнными языками были различные диалекты немецкого. В те времена Германия ещё не являлась нацией. Большую часть Средневековья она провела как рыхлая федерация королевств, княжеств, великих герцогств и вольных городов под номинальной властью императоров Священной Римской империи. А затем, вскоре после того как Ренессанс успел пустить там глубокие корни, обрушился апокалиптический ужас Тридцатилетней войны (1618–1648) — эпоха невообразимо жестоких религиозных войн, в ходе которых большинство европейских держав использовали немецкие земли как удобную площадку для взаимного истребления, уничтожив в процессе треть их населения.
Германские земли вышли из этой травматической эпохи как пояс астероидов из независимых государств-карликов, более или менее вращавшихся вокруг двух конкурирующих центров: Вены — столицы элегантной, циничной, католической Австрии, и Берлина — столицы суровой, серьёзной, лютеранской Пруссии. Австрия граничила с Италией и была причастна к возрождению греческой и римской культуры с довольно раннего периода; Пруссия не граничила, и причастна не была, но компенсировала это типично прусским твердолобым упрямством. В результате немецкие земли погрузились в изучение классической древности с таким рвением, что остальные европейские нации только диву давались. «Тирания Греции над Германией», по меткому выражению английского историка Э. М. Батлер, явилась масштабным культурным феноменом во всех немецкоязычных странах на протяжении XVIII и XIX веков. «Немцы подражали грекам рабски; они были одержимы ими повальнее и ассимилировали их меньше, чем какой-либо иной народ», — писала она, и была совершенно права.
 Древняя Греция, которой никогда не существовало…
Древняя Греция, которой никогда не существовало…
Это означало, помимо прочего, что на протяжении почти двух столетий большинство немецких интеллектуалов считали само собой разумеющимся, что для получения надлежащего образования первостепенной задачей является забыть как можно больше собственного культурного наследия и заменить его на чучело греческой и римской культур. Это привело к расколу немецкого общества на тех, кто претендовал на статус образованных людей, и тех, кто на него не претендовал. Вспомните, как американский средний класс сегодня приучают ненавидеть, бояться и презирать рабочий класс собственной страны — то же самое было до боли знакомо и во всей Германии в те времена.
Разумеется, спустя примерно столетие произошло неизбежное: значительное число интеллектуалов-диссидентов начало нарушать субординацию, восставать против неизбежной посредственности и лицемерия элит своего времени и искать альтернативы, делая ставку на максимальное оскорбление общепринятых устоев эпохи, настолько, насколько им это сходило с рук. (Те из моих читателей, кто следит за современной американской сценой, без труда проведут параллели.) Именно тогда слова «классицизм» и «романтизм» навсегда вошли в лексикон западной культуры.
Раскол между ними был порождением постренессансной эпохи. Большинство великих художественных и творческих начинаний Ренессанса пытались соединить классическое наследие с культурными формами позднесредневековой Европы. Когда эти попытки синтеза потерпели крах — а рано или поздно они его потерпели, — возникло непрекращающееся противостояние между теми, кто стремился подражать классическому наследию как можно точнее, и теми, кто хотел сохранить жизненную силу европейских культурных форм. Первые составили движение классицизма, вторые — романтизма, и с того момента каждый художник, писатель, поэт, композитор и интеллектуал в Европе оказывался где-то на этом спектре.
 …и Средневековье, которого тоже никогда не существовало. Знакомая история.
…и Средневековье, которого тоже никогда не существовало. Знакомая история.
Эта полярность имела ещё одно измерение, вытекавшее из того, как античная и средневековая культуры были восприняты в раннее Новое время. Так случилось, что значительная часть дошедшей до нас из Древней Греции литературы была философской, и чаще всего эта философия была превосходной. Это привело к переоценке философской стороны древнегреческой культуры. В самой Древней Греции философы были лишь одной маленькой интеллектуальной субкультурой среди многих, но в глазах европейцев XVIII–XIX веков как раз эта деталь была утрачена, и Греция превратилась в воображаемую утопию совершенного разума. Как следствие, классицисты были одержимы логикой, разумом и подавлением сильных эмоций.
Романтики, в свою очередь, кинулись в противоположную крайность и избрали Средневековье в качестве образца для подражания. По иронии судьбы, средневековая культура была погружена в логику и разум ничуть не меньше, чем древнегреческая; современные историки логики, собственно, называют позднее Средневековье одной из великих эпох для логики, поскольку средневековые философы проделали огромную и плодотворную работу, развивая основы, заложенные греческой логикой. Романтики полностью проглядели это. Для них Средневековье было целиком связано с религиозной преданностью, куртуазной любовью, готическими соборами и народной традицией, не обременённой толстой коркой классического рационализма.
И вот так получилось, что по всей Европе люди классического склада взывали к такой Древней Греции, которой не существовало, а люди романтического склада — к такой средневековой Европе, которой тоже не существовало. Классически настроенные возвеличивали разум и подавление страстей, романтически настроенные — традицию и упоение страстями. Это была великолепная иллюстрация того факта, что противоположность одной плохой идеи обычно оказывается другой плохой идеей, и всё это породило горы скверного искусства наряду со значительным потоком очень, очень хорошего. Иными словами, все получилось так, как оно обычно получается с культурными явлениями.
 «Черепаха и заяц» — одна из историй Эзопа. Дети читают их до сих пор, и не случайно.
«Черепаха и заяц» — одна из историй Эзопа. Дети читают их до сих пор, и не случайно.
Однако борьба классицизма с романтизмом имела и ещё одно последствие для европейских культур, и здесь мы начинаем возвращаться к Зигфриду, Брюнхильде и золоту на дне Рейна. Классицисты обладали огромным преимуществом на раннем этапе: у них было множество первоклассных творений. «Илиада» и «Одиссея» Гомера — грандиозные эпические повествования, блестяще написанные; «Энеида» Вергилия лишь немного уступает им; к этому добавьте все великие греческие драмы, массу прекрасной греческой и латинской поэзии — и так вплоть до басен Эзопа, которыми потчивали детей с ранних лет, привавая им вкус к плодам античности.
Романтикам нужно было найти что-то сопоставимое. К их счастью, Средневековье было уже свершилось, ждало и жаждало заполнить пробел, а в Германии — из-за резни и культурной разрухи Тридцатилетней войны — Средневековье казалось совсем не далёким прошлым по состоянию на 1800-й год. И тут на сцену выходят Якоб и Вильгельм Гримм, два брата с пристрастием к народным сказкам. Оба были способными учёными с отличными лингвистическими навыками, у обоих был обширный круг друзей, и обоих глубоко вдохновляли романтические идеи. И вот они с друзьями принялись собирать столько старых немецких народных сказок, сколько только могли найти. Именно благодаря им вы слышали о Красной Шапочке, Золушке, Белоснежке, Гензеле и Гретель и множестве других персонажей, населяющих детское воображение по сей день. Да, до Гриммов все эти персонажи были безвестными героями историй, рассказываемых лишь в глухих уголках сельской Германии.
В последние годы начали раздаваться сетования по поводу того, что братья Гримм и компания довольно часто переписывали собранные ими истории. Да, так и было, но в те времена это было нормой; нынешняя привычка обвинять прошлое в несоблюдении норм настоящего — один из многих признаков нашего всепроникающего современного хроноцентрического снобизма. Что на самом деле впечатляет в сказках братьев Гримм так это то, как мало они их редактировали, даже когда истории были построены вокруг таких тем, как каннибализм, насилие, инцест и убийство. Это не чистенькие выхолощенные истории из тех, что выдавливаются из корпоративных отверстий в скучающее воображение сегодняшних детей. Они буйные, грубые, дикие и первобытные, именно поэтому они пользуются таким бешеным успехом у детей с момента публикации. Они тянутся сквозь века к таким архаичным культурным пластам, что маленькие свирепые зверьки, которых мы зовём «детьми», мгновенно находят с ними общий язык.
 Гензель и Гретель в лесу. У Эзопа наконец появился серьёзный конкурент.
Гензель и Гретель в лесу. У Эзопа наконец появился серьёзный конкурент.
Но Märchen — «волшебные сказки» было бы неточным названием, поскольку далеко не во всех из них фигурируют волшебные существа — собранные братьями Гримм были лишь частью средневекового наследия, обнаруженного немецкими романтическими учёными. Ещё была и «Песнь о Нибелунгах» — одно из великих произведений средневековой немецкой литературы. Был целое море артуровских повествований на древних немецких диалектах — истории о короле Артуре пользовались бешеной популярностью по всей средневековой Европе, — и лучшим среди них был, пожалуй, «Парцифаль» Вольфрама фон Эшенбаха — яркая и захватывающая версия легенды о Граале. Были средневековые легенды, укоренённые в истории, вроде великого состязания миннезингеров в Вартбурге или замечательной истории Ганса Сакса, поэта-сапожника из средневекового Нюрнберга. Это был богатейший материал, не уступающий лучшему, что могли предложить Англия и Франция.
В последние годы начали раздаваться сетования по поводу того, что братья Гримм и компания довольно часто переписывали собранные ими истории. Да, так и было, но в те времена это было нормой; нынешняя привычка обвинять прошлое в несоблюдении норм настоящего — один из многих признаков нашего всепроникающего современного хроноцентрического снобизма. Что на самом деле впечатляет в сказках братьев Гримм так это то, как мало они их редактировали, даже когда истории были построены вокруг таких тем, как каннибализм, насилие, инцест и убийство. Это не чистенькие выхолощенные истории из тех, что выдавливаются из корпоративных отверстий в скучающее воображение сегодняшних детей. Они буйные, грубые, дикие и первобытные — именно поэтому они пользуются таким бешеным успехом у детей с момента публикации. Они тянутся сквозь века к таким архаичным культурным пластам, что маленькие свирепые зверьки, которых мы зовём «детьми», мгновенно находят с ними общий язык.
Гензель и Гретель в лесу. У Эзопа наконец появился серьёзный конкурент.
Но Märchen — «волшебные сказки» было бы неточным названием, поскольку далеко не во всех из них фигурируют волшебные существа — собранные братьями Гримм были лишь частью средневекового наследия, обнаруженного немецкими романтическими учёными. Ещё была и «Песнь о Нибелунгах» — одно из великих произведений средневековой немецкой литературы. Был целое море артуровских повествований на древних немецких диалектах — истории о короле Артуре пользовались бешеной популярностью по всей средневековой Европе, — и лучшим среди них был, пожалуй, «Парцифаль» Вольфрама фон Эшенбаха — яркая и захватывающая версия легенды о Граале. Были средневековые легенды, укоренённые в истории, вроде великого состязания миннезингеров в Вартбурге или замечательной истории Ганса Сакса, поэта-сапожника из средневекового Нюрнберга. Это был богатейший материал, не уступающий лучшему, что могли предложить Англия и Франция.
Одним из персонажей, обнаруженных во всей этой прекрасной средневековой прозе, был Альберих. Его имя означает «король эльфов» на древнейшем немецком: albe — «эльф», а rich — родственно латинскому rex, санскритскому раджа и словам со значением «король» в других индоевропейских языках. В немецких легендах он — карлик, владеющий волшебными сокровищами и время от времени одаривающий ими героев. В «Песни о Нибелунгах» Зигфрид побеждает его, после чего Альберих ему служит.
Но в древних немецких легендах есть и другой персонаж с очень похожим именем — Erlkönig (буквально «король ольхи», но, вероятно, происходящий от датского Ellerkonge — «король эльфов»). Это ужасающий всадник, преследующий путников в лесу и убивающий их одним прикосновением. У этого же устрашающего всадника в немецких легендах есть и другое имя: Вуотан или Вотан. Это эхо языческого бога сохранялось в немецком фольклоре вплоть до Нового времени — ещё одно напоминание о том, как долго длилось Средневековье в более изолированных областях Центральной Европы. Запомните этих двоих, мы ещё много о них услышим.
Всё это было собрано немецкими романтиками к середине XIX века, и тут скандинавские эпосы Старшей и Младшей Эдды обрушились с далёкого севера, как молот самого Тора, и оставили след, который не изгладился по сей день.
 Тор, каким его представляли в XIX веке.
Тор, каким его представляли в XIX веке.
Ещё в конце XVII века европейские учёные начали осознавать, какие необычайные литературные сокровища скрываются в исландских источниках. Следующие полтора века они оставались достоянием узкого учёного мира. Карл Зимрок изменил это положение. Он был ещё одним романтическим интеллектуалом в духе Гриммов, и его страстью были древние эпосы; именно он сделал первый перевод «Песни о Нибелунгах» на современный немецкий (и оказал ту же услугу множеству других средневековых немецких текстов). В 1850-м году он опубликовал первый немецкий перевод Старшей Эдды, самого влиятельного из исландских текстов.
Как обычно, Рихард Вагнер был здесь на шаг впереди, хоть и ненамного. Его первые эссе об истории нибелунгов — Der Nibelungen-Mythus als Entwurf zu einem Drama («Миф о нибелунгах как набросок к драме») и Die Wibelungen: Weltgeschichte aus der Saga («Вибелунги: Всемирная история, рассказанная сагой»), — оба вышли в печать в 1848-м году. Первое из них, по сути, представляет собой краткое содержание четырёх опер Кольца, не слишком отличающееся от окончательной версии. Второе — весьма странное эссе об истории, символизме и мифе; мы подробно обсудим его в одном из следующих постов, поскольку оно предлагает важнейший ключ к пониманию того, что Вагнер делал в «Кольце», а также в «Парсифале».
Для наших текущих целей важно то, что Вагнер был погружён в легенду о нибелунгах по самые уши к тому моменту, когда перевод Зимрока сделал скандинавскую мифологию неотъемлемой частью немецкой культуры. Вагнер был, по сути, архиромантиком: одним из величайших романтических композиторов (а великих романтических композиторов было немало) и вдобавок глубоко погружённым в более широкие сферы романтической литературы, поэзии, культуры,… и политики.
 Романтическая политика? Ещё какая. Подробности — впереди.
Романтическая политика? Ещё какая. Подробности — впереди.
Да, есть такая вещь, романтическая политика. В одном из следующих постов мы поговорим о ней подробно, потому что именно из неё вырос домарксовый социализм, а также немало других культурных и социальных явлений. И всё это совершенно не устарело сегодня. Совсем наоборот: как мы увидим, та самая романтическая политика и культура, которая формировала мысль и искусство Рихарда Вагнера (среди многих других), прочно присутствует по всему современному западному миру и с регулярностью вспенивается на поверхности. Тот факт, что заканчивается это вспенивание всегда одинаково, ничуть не замедляет неизбежный поворот к романтической политике, стоит возникнуть подходящим условиям.
Точно так же и классицизм прочно укоренён в современной культуре, но с одной поправкой. В первой половине XX века, по целому каскаду сложных причин, коренившихся отчасти в культурных переменах, отчасти в великих технологических трансформациях эпохи, классицизм утратил свою фиксацию на греко-римской культуре и перенёс свои представления об обществе логики и разума на науку и технологии. Вместо Афин и Рима воображаемое будущее технологического всемогущества стало тем золотым веком, к которому обратили свой обожающий взор приверженцы классицистских установок.
Именно тогда старшеклассники по всем Соединённым Штатам перестали учить латынь и начали посещать уроки естественных наук. Именно тогда общественные здания перестали украшать каннелированными колоннами и мраморными фронтонами в римском стиле и превратились в полигон для архитекторских представлений о том, как должны выглядеть «футуристические» здания. Тоги ушли, пришли скафандры, но в подспудных установках мало что изменилось, не говоря уже о том невыносимом самодовольстве, с которым новый классицизм прогресса взирал на свои идеи и воображаемый мир, выстроенный из них.
 Классицизм XX века: больше реактивных ранцев, меньше тог, но суть та же.
Классицизм XX века: больше реактивных ранцев, меньше тог, но суть та же.
Тем временем, как уже было отмечено, романтизм не изменился ни на йоту. Именно поэтому, дорогой читатель, художественная литература в западном мире по-прежнему расколота между насквозь классическим жанром научной фантастики, одержимым логикой, разумом и славным маршем науки и технологий, и неизлечимо романтическим жанром фэнтези, навечно застрявшим в том же псевдосредневековом антураже, которым так глубоко восхищались романтические друзья и соперники Вагнера. Иными словами, не случайно самое коммерчески успешное из всех произведений романтической художественной литературы — «Властелин колец» Дж. Р. Р. Толкина — черпает из того же корпуса архаичных германских легенд и преданий, которые дали Вагнеру исходный материал для его оперного цикла.
Здесь таится глубокая ирония. Европейские культуры, зародившиеся тысячу лет назад на руинах Римской империи и пятьсот лет назад хлынувшие из своего сурового и студёного субконтинента на завоевание мира, родились из столкновения между угасающими средиземноморскими культурами Греции и Рима, с одной стороны, и нарастающей волной германских варваров, поглотивших их, с другой. В Средние века эти два потока слились, породив уникальную гибридную культуру; в эпоху Ренессанса между ними впервые проявились непримиримые противоречия; в последующие столетия раскол между классицизмом и романтизмом становился всё более выраженным, меняясь по форме, но не по существу.
А что же сейчас? До этого мы ещё доберёмся, тем более что и сам Вагнер имел на этот счёт пророчество.
Оригинал статьи: The Nibelung’s Ring: The Rediscovery
30 Jan 2025
Представьте на мгновение, что на дворе 2124-й год, и Соединённые Штаты Америки кувыркаются на последних этапах затяжного падения. Наркокартели, расположившиеся вдоль южной границы, давно превратились в частные армии под командованием могущественных военачальников. Во время вспышки гражданской войны в США один из них объединяет под своим началом нескольких менее влиятельных боссов и проведя объединённые силы сквозь рушащиеся пограничные укрепления, захватывает большую часть Калифорнии, провозглашая её своим личным королевством. Остатки федерального правительства, перебравшиеся в Цинциннати после того, как повышение уровня моря превратило Вашингтон в солончаковые болота, слишком слабы и поглощены другими кризисами, чтобы оказать сопротивление.
 А вот и они.
А вот и они.
Несколько десятилетий спустя тот же военачальник отправляется расширять своё королевство, двигаясь на восток через Аризону и Нью-Мексико, чтобы вторгнуться в Техас, где несколько уцелевших нефтяных скважин всё ещё дают нефть, в которой отчаянно нуждаются остатки Соединённых Штатов. В ответ жёсткий и безжалостный американский генерал — последний способный командующий, оставшийся у США, — собирает армию, состоящую в основном из западноафриканских наёмников, и начинает масштабное контрнаступление.
Начинается резня. В серии жестоких сражений силы военачальника разгромлены, его недолговечное королевство рушится, а сам он погибает под градом пуль. Это всего лишь один эпизод из многих в кровавых сумерках умирающей нации, ненадолго отсрочивший окончательный крах США. Однако он привлекает внимание менестрелей. В последующие века история военачальника, завоевавшего Калифорнию, становится ядром целого цикла легенд. Спустя более тысячи лет эти легенды вдохновляют создание одного из величайших произведений искусства в мире.
 Современный образ Гундакара. Да, он был крут.
Современный образ Гундакара. Да, он был крут.
Измените несколько деталей, перенесите действие на столетия назад, во времена падения другой империи — и вот как рождается история, лёгшая в основу «Кольца Нибелунга». Военачальника звали примерно Гундакар. Он был королём германского племени бургундов, успевшего дать название части современной Франции, прежде чем их почти полностью не истребили. В 406-м году бургунды перешли Рейн на римские земли и основали там своё королевство. Сам Гундакар впервые упоминается в римских хрониках в 411 году, когда он и другой король-варвар поддержали одну из сторон в кровавой гражданской войне, терзавшей позднюю Римскую империю. В 413 году, после поражения своей стороны, Гундакар и его народ заключили сделку с ослабленными победителями, которая закрепила их власть над значительной частью римских территорий к западу от Рейна.
В 435 году Гундакар, видимо, решил, что этого недостаточно, и снова вторгся на римские территории, приблизившись к стратегическим районам северной Галлии. На этот раз ему противостоял более опасный противник: Флавий Аэций, последний способный полководец Западной Римской империи. Аэций родился в римской аристократической семье, но юность провел в качестве заложника в «варварских» землях — сначала при дворе короля вестготов Алариха I, затем при дворе Ульдина, короля гуннов, и его преемника Харатона. Этот опыт закалил его, сделав находчивым, умелым воином и стратегом, с близкими связями среди варварских племён и глубоким пониманием их обычаев. Всю свою карьеру, используя запутанные союзы той эпохи, он набирал и возглавлял армии из самих варваров.
 Ещё более современный образ Флавия Аэция. Он был ещё суровее. (Да, сегодня он стал персонажем компьютерной игры Rise of Kingdoms.)
Ещё более современный образ Флавия Аэция. Он был ещё суровее. (Да, сегодня он стал персонажем компьютерной игры Rise of Kingdoms.)
Именно так он и поступил, когда Гундакар вторгся в Галлию. Аэций быстро собрал армию гуннов и выступил против него. В двух жестоких кампаниях 436-го и 437-го годов он разгромил бургундов, убив Гундакара и 20 000 его бургундских воинов. Выжившие сдались Аэцию и были переселены в регион к югу от Женевского озера, где быстро перемешались с местными племенами. Аэцию предстояло ещё множество битв, прежде чем император, которому он служил, приказал его убить — верность Римской империи в те дни была небезопасным выбором. Его победа над Гундакаром стала лишь одним эпизодом в кровавых сумерках империи, отсрочившим падение Запада на несколько десятилетий. Однако гибель Бургундского королевства привлекла внимание сказителей, и так родился цикл легенд.
Гунтер (как со временем стали звать этого вождя) привнёс в историю больше, чем просто кровавый конец. Согласно хроникам, он был Гибихунгом — то есть сыном или внуком более раннего бургундского короля Гибиха. Его также называли Нибелунгом. Сегодня точное значение этого слова в эпоху Гунтера неизвестно, но, вероятно, оно связано с современным немецким Nebel — «туман». Если так, то «Нибелунг» означает «дитя тумана». Отголосок забытой архаичной мифологии? Вполне возможно, но мы вряд ли узнаем наверняка. Запомните эти титулы — они ещё встретятся нам.
Устная традиция — штука странная. Она может сохранять осколки знаний из глубин времён: например, аборигены северного побережья Австралии и жители западных островов Шотландии хранят точные сведения о очертаниях береговых линий, существовавших 10 000 лет назад, когда уровень моря был на 90 метров ниже. Но при этом устная традиция так же бесцеремонно смешивает факты, если это помогает приукрасить историю. Мерлин, к примеру, почти наверняка был реальной личностью, но жил на два поколения позже исторического короля Артура и не имел к его недолговечному королевству никакого отношения; он служил Гвенддолау, последнему языческому королю низменностей Шотландии. Однако когда Арторий, римско-британский генерал, превратился в сияющий образ короля Артура, его легенда стала магнитом для других британских преданий. Мерлин — лишь один из многих когда-то отдельностоящих персонажей, втянутых в орбиту артурианы. Со временем легенды об Артуре вобрали в себя множество изначально независимых сюжетов.
 Ни у кого нет ни малейшего представления о том, как выглядел Аттила Гунн. Но этот образ передаёт общее впечатление.
Ни у кого нет ни малейшего представления о том, как выглядел Аттила Гунн. Но этот образ передаёт общее впечатление.
Это же произошло и с историей Гунтера и падением Бургундского королевства. Гуннские наемники, свергшие Гунтера, позаботились о том, чтобы сказители, взявшись за дело, вплели в сюжет самого Аттилу Гунна. У них была отличная завязка для этой части легенды. После долгой жизни, полной завоеваний и грабежей, старый гуннский король женился на юной златовласой варварке, чье имя, согласно римским хроникам, было Ильдико. На рассвете после свадебной ночи он был мертв. Неизбежно поползли слухи, что она убила его — теории заговора существуют с незапамятных времен — и со временем это утверждение слилось с участием гуннов в падении Гунтера, породив легенду: Ильдико якобы была сестрой Гунтера и убила Аттилу, чтобы отомстить за брата.
Эта история, вероятно, имела хождение уже к концу V века. Имя Ильдико исчезло из преданий, а мнимой сестре Гунтера дали как минимум два других имени — Гримхильд и Гутруна. У него появился брат или кузен Хаген, о котором шла дурная слава. А еще у него появилось сокровище. Некоторые авторы предполагают, что оно у него могло быть и на самом деле, ведь варварские короли той эпохи имели доступ к богатой добыче, а во время заката Римского мира накопленные за века драгоценные металлы легко могли оказаться в руках удачливого авантюриста. Как бы то ни было, сокровище Гунтера стало центральным мотивом его истории. Поползли легенды, что Аттила убил Гунтера, чтобы завладеть сокровищем, но тот спрятал его так хорошо, что сокровище так и не нашли. Поздние сказители добавили, что Гунтер навеки скрыл его, кинув в Рейн.
 Брунехильда была чем-то вроде вот этого, но только с морем крови, заливавшими декорации.
Брунехильда была чем-то вроде вот этого, но только с морем крови, заливавшими декорации.
Прошел еще век, прежде чем в повествовании появилась Брюнхильда — следующий участник истории. Её настоящее имя было Брунехильда, и она была готкой — и нет, это не значит, что она носила чёрную одежду и жирно подводила глаза чёрным. Она была дочерью вестготского короля Атанагильда и родилась около 543-го года в Толедо, столице вестготов после их завоевания Испании. Достигнув брачного возраста, она вышла за Сигиберта I, короля Австразии — одного из четырех королевств, созданных франками на территории римской провинции Галлия. Её жизнь была долгой, запутанной и кровавой; если кратко: её сестра, выданная за короля соседнего Нейстрийского королевства, была убита нейстрийским королем по наущению его любовницы Фредегонды. Брунехильда ответила кампанией эпической мести.
В течение следующих нескольких десятилетий, продолжая кровавую вражду с Фредегондой, пережив убийство мужа и гибель множества других людей, а затем сполна расплатившись с противницей тем же, Брунегильда трижды правила Австразией — каждый раз в качестве регента при разных малолетних принцах — и каждый раз была свергнута. По её приказу были убито внушительное число врагов: согласно современным ей хроникам, среди её жертв только франкских королей числились десять человек, а также множество людей менее знатного происхождения. Когда же её наконец окончательно победили, то, в зависимости от того, какой хронике верить, победители либо разорвали её на части дикими лошадьми, либо тащили лошадью по каменистой горной дороге пока они не умерла.
Её железная воля, бурная жизнь и жестокая смерть гарантировали, что она станет легендарной фигурой. Предания о ней неизбежно отдалились от исторических событий и, дрейфуя сквозь годы, слились с легендой о королевстве Гунтера и его падении. Во время этой трансформации суровые реалии политической борьбы в Австразии эпохи темных веков канули в лету, оставив лишь несколько следов: имя героини, её необычайную силу воли, страсть к мести и тот факт, что её смерть была связана с лошадью.
Затем был Зигфрид. Его корни уходят гораздо, гораздо глубже эпохи варварских вождей, породивших Гунтера и Брунгильду, и, скорее всего, он вообще никогда не существовал как историческая личность. В мифах и легендах древней индоевропейской диаспоры, от Индии до Ирландии, разбросаны осколки древней истории о сияющем герое-боге, который сражается с жадным богом подземного мира, чтобы освободить магическое сокровище, связанное с плодородием земли. В древнейшие времена, когда индоевропейцы жили примерно там, где сейчас Украина, это, вероятно, был простой сезонный миф: герой — золотое солнце, рожденное во тьме середины зимы, взрослеющее и убивающее дух зимы.
 Индра поражает Вритру о освобождает воду.
Индра поражает Вритру о освобождает воду.
В Индии, где угрозой плодородию была засуха, а не холод, миф превратился в битву между богом-воином Индрой и мрачным змеем Вритрой, удерживающим воды. В иранском мифе аналогом Вритры стал Веретрагна, игравший схожую роль в до-зороастрийские времена. В славянских легендах этот же образ воплотился в бога плодородия Велеса, а в древнейших пластах римской мифологии — в Веиовиса, подземного Юпитера, повелителя скота и земных богатств, против которого громовержец Юпитер ведет сезонную войну.
Однако на холодном севере зимний дух сохранил ужасную змеиную форму Вритры, а роль убийцы драконов постепенно перешла к двум величайшим героям северных легенд — Беовульфу и Зигфриду. Если в других странах солнечный герой после победы восходил к славе и успеху, то северные предания приобрели мрачный оттенок. Здесь сокровище стало проклятием. Беовульф убивает своего дракона с помощью храброго юного Виглафа, но умирает от ран, и без его сильной руки, защищавшей народ, драконий клад привлекает столько набегов из дальних земель, что могучее королевство гётов гибнет навсегда. Что же до Зигфрида— об этом мы еще расскажем. Пока скажем лишь, что он встречает жалкую смерть вскоре после подвига с драконом, а завоеванное им сокровище теряется навеки.
 Помните, как все в Средиземье устремились к Одинокой горе после гибели Смауга? Толкин понимал, о чём писал.
Помните, как все в Средиземье устремились к Одинокой горе после гибели Смауга? Толкин понимал, о чём писал.
Возможно, это просто отражение реалий, связанных с кладами драгоценных металлов в эпоху насилия. Богачи совершают множество ошибок на закате цивилизаций, но одна из самых распространённых — попытка сохранить богатство, превратив его в драгоценности и спрятав. Это лишь гарантирует, что каждый местный вождь, варварский отряд или группа повстанцев узнает: золото и украшения можно легко забрать, стоит лишь схватить богача с его семью и, начав с детей, пытать, чтобы выведать, где спрятаны сокровища. (Несомненно, что и нынешние поклонники драгметаллов со временем узнают это на собственном горьком опыте.) Смысл образа проклятого клада в подобные времена понятен — он преподаёт суровый практический урок. Однако, как мы увидим, с веками этот урок обрёл новые смыслы.
Так Зигфрид, убийца дракона, вырвавшись из мира сезонных мифов, вплыл в легенды, где встретил Гюнтера — обречённого короля с сестрой Гутруной, его мрачным братом Хагеном и сияющим сокровищем, отголоском золота летнего урожая, которое некогда освободил солнечный герой. Похоже, он и Брунгильда — величественно ужасная королева-мстительница — прибыли примерно в одно время. Менестрели тут же решили, что эти двое созданы друг для друга.
 Версия средневекового рыцарского романа.
Версия средневекового рыцарского романа.
Вероятно, что к примерно 1000-му году, повествование обрело свою классическую форму. Оригинальная версия давно утрачена, но до наших дней дошли два объёмных произведения, основанных на ней: «Песнь о Нибелунгах» (нем. Nibelungenlied) в Германии и «Сага о Вёльсунгах» (исл. Volsungasaga) в Исландии. Эти версии отнюдь не идентичны. «Песнь о Нибелунгах» — изысканный рыцарский роман, который легко встал бы в один ряд с легендами о короле Артуре, тогда как «Сага о Вёльсунгах» — мрачная и жестокая история, наполненная почти непрерывной резнёй.
Сюжеты их также существенно различаются, хотя некоторые основные темы общи для обеих. Там есть Зигфрид (в исландской версии — Сигурд), герой-убийца дракона, рождённый вдовой после гибели его отца, Зигмунда. Зигфрид золотоволос, силён, красив и бесстрашен, его тело неуязвимо для ран — кроме неизбежного уязвимого места на спине. Там есть дракон, которого он убивает, и несметное золотое сокровище, взятое из логова чудовища. Там есть Брюнхильда (в исландской версии — Брюнхильд), женщина-воительница, обладающая сверхъестественной силой. Там есть Гунтер (в саге — Гуннар). Там есть Кримхильда (в саге — Гудрун), сестра Гунтера. Вот Хаген (или Хёгни), ждущий со своим копьём. И наконец, где-то вдали маячит Аттила Гунн (в «Песни о Нибелунгах» — Этцель, в «Саге о Вёльсунгах» — Атли).
В центре обеих вариаций — простая история. Зигфрид, только что победивший дракона, прибывает ко двору Гунтера и влюбляется в Гутруну (так сестру назовёт Вагнер). Гунтер хочет жениться на Брюнхильде, но та согласна выйти только за героя, а Гунтер не соответствует её требованиям. Гунтер обещает Зигфриду разрешить брак с Гутруной, если тот поможет ему завоевать Брюнхильду. Зигфрид соглашается, использует волшебный колпак из сокровищницы дракона, чтобы принять облик Гунтера, и совершает необходимые подвиги. Брюнхильда выходит замуж за Гунтера, Зигфрид женится на Гутруне — и кажется, всё идёт хорошо.
 Куда более кровавая норвежская версия. (Да, в переводе того самого Уильяма Морриса. Его таланта хватило бы на два десятка менее одарённых людей.)
Куда более кровавая норвежская версия. (Да, в переводе того самого Уильяма Морриса. Его таланта хватило бы на два десятка менее одарённых людей.)
Брунгильда и Гутруна вступают в спор, как это сделали Брунехильда и Фредегонда. Выясняется, что воительницу победил не Гунтер, а Зигфрид; Брунгильда, кипящая яростью, вступает в сговор с Хагеном, который берёт Зигфрида на охоту и пронзает копьём уязвимое место на его спине, убивая. Брунгильда совершает самоубийство и вместе с Зигфридом сгорает на погребальном костре. Гунтер и Хаген забирают сокровище Зигфрида. Гутруна же выходит замуж за Аттилу Гунна и безжалостно использует его как орудие мести против брата и Хагена, манипулируя надеждой на сокровище дракона. Однако Хаген догадывается о её планах и сбрасывает золотое сокровище, добытое Зигфридом у дракона, в Рейн, где оно теряется навсегда. Затем— ну, если вкратце, то все погибают.
Если не считать последней детали, это совсем не похоже на историю Гундахара, варварского военачальника, и его недолговечного Бургундского королевства. Однако интересно, что все великие эпосы, рождённые в тёмные века Европы, заканчиваются именно так. Артуровский цикл, самый знаменитый из них, — это хроника грандиозного провала, золотого королевства, рухнувшего из-за личных недостатков тех, кто должен был его хранить. Французская «Песнь о Роланде» и валлийская «И Гододдин» повествуют о горьких поражениях, вызванных самонадеянной гордыней лидеров проигравшей стороны — и в обоих случаях эти лидеры являются героями повествования. Великий цикл подвигов датских воинов, от которого сохранился лишь фрагмент «Беовульфа», также рассказывает о золотых днях великого королевства и его кровавом конце. История, которую забытые барды сплели из судеб Гунтера, Брунгильды и древнего мифа о Зигфриде-солнечном герое, скроена из той же материи.
 В европейских легендах финал всегда был предрешён. Подробности? Мы к ним ещё вернёмся.
В европейских легендах финал всегда был предрешён. Подробности? Мы к ним ещё вернёмся.
Тёмные века рождают эпосы, но не все они завершаются катастрофой. Можно вспомнить «Одиссею», хоть и созданную в мрачные времена после краха позднего бронзового века в восточном Средиземноморье, но которая заканчивается тем, что Одиссей триумфально возвращается домой. Однако холодный шёпот грядущей гибели, кажется, витал над европейским проектом с самых первых его шагов в постримскую эпоху. Когда «Песнь о Нибелунгах», «Сага о Вёльсунгах» и прочие памятники древнегерманской литературы вырвались из вековой безвестности и грянули, как гром, над головами Европы XIX века, они принесли с собой именно такое ощущение. В первоначальном замысле «Кольца нибелунга» Рихард Вагнер попытался это подправить, предрекая гибель только тех некоторых сторон индустриального общества, которые он лично ненавидел. Однако, как мы увидим, легендами было уготовано язвительно посмеяться последними.
Оригинал статьи: The Nibelung’s Ring: The Legends
27 Jan 2025
(Музыкальная тема: «Увертюра» из «Золота Рейна» Вагнера)
Несколько лет назад, когда я ещё вёл блог «The Archdruid Report», я вскользь упомянул, что если мне когда-нибудь надоест иметь большую аудиторию, я начну серию постов о тетралогии Рихарда Вагнера «Кольцо нибелунга». Это отчасти было шуткой, но только отчасти, и по разным причинам я решил осуществить эту задумку сейчас, не обращая внимания на то, как это отразится на количестве посещений этого сайта. Во многих смыслах мы живём в вагнеровские времена: смесь подлинного творческого гения и помпезного, эгоцентричного пустозвонства, определяющая искусство и жизнь Вагнера, в не меньшей степени характеризует западное индустриальное общество, хотя большинство его обитателей предпочитают об этом не задумываться. Чувство утраченного величия и надвигающейся гибели пронизывающее «Кольцо нибелунга», сегодня вполне отчётливо звучит в фоновом музыкальном сопровождении к нашей эпохе.

Из графической адаптации П. Крейга Рассела. Сколько опер вы знаете, у которых есть графические новелизации?
Для тех, кто не знает, «Кольцо нибелунга» (сокращённо Кольцо) — это цикл из четырёх взаимосвязанных опер, написанных немецким композитором и либреттистом Рихардом Вагнером (1813–1883). Русские названия таковы: «Золото Рейна», «Валькирия», «Зигфрид» и «Гибель богов». Вместе они образуют самое грандиозное творение западной традиции: симфоническую композицию для полного оркестра, исполнение которой занимает более четырнадцати с половиной часов, дополненную драматической поэмой аналогичного масштаба и всеми театральными деталями, необходимыми для постановки всей тетралогии как оперной драмы на протяжении четырёх вечеров.
И это лишь самый очевидный показатель масштабности Кольца, как культурного явления. Как некоторые читатели уже знают, а другие догадались по названиям, Вагнеровская драма основана на германской мифологии и легендах. Автор заимствовал сюжеты из двух версий одной и той же древней истории — «Песни о нибелунгах» из средневековой Германии и «Саги о Вёльсунгах» из средневековой Исландии, обе из которых восходят к кровавым событиям последних лет Римской империи.

Современная постановка Орфея. Стареет достойно.
Для опер того времени не было ничего необычного в заимствовании древних легенд. Самая старая сохранившаяся опера, «Орфей» Клаудио Монтеверди (премьера в 1607-м году), основана на греческой мифологии, и многие другие композиторы до Вагнера следовали по стопам Монтеверди. Однако обычно подход заключался в том, чтобы найти изящную историю, переложить её в стихи, добавить музыку — и готово. Вагнер действовал иначе. Он сам писал все свои либретто (так называют текст оперы) и готовился к задаче создания Кольца, погружаясь в мир древнегерманской мифологии, одержимо читая оригинальные тексты и поглощая каждую крупицу научной литературы по теме, которую мог выпросить, одолжить или украсть. Одним из результатов такого подхода является тот факт, что любой, кто знаком с Эддами и посетит постановку Кольца, заметит множество отсылок к древнескандинавской литературе.
Фридрих Ницше. На него Вагнер повлиял глубоко.
Однако это не было единственным ингредиентом в рецепте Кольца. Вагнер… мы обсудим его отталкивающие стороны в скором времени, хорошо? Сначала я хочу обсудить причины, по которым Кольцо заслуживает внимания… так вот Вагнер, как я уже говорил, уникален среди великих композиторов тем, что на него в первую очередь влияли не музыканты. Два главных вдохновителя этих четырёх опер были философами. Многие знают, что Вагнер и Фридрих Ницше были близкими друзьями, и это действительно так, но Ницше не влиял на Вагнера; это Вагнер влиял на Ницше, и даже после разрыва сам Ницше неоднократно признавал в письмах, что годы дружбы с Вагнером стали для него одним из важнейших интеллектуальных опытов. Подобная оценка одним из самых влиятельных философов современности говорит о многом.
Главными философскими вдохновителями Вагнера были два других человека. Людвиг Фейербах, о котором сегодня почти никто не помнит, но чьи идеи пропитали всю нашу культуру, был ориентиром для молодого Вагнера, когда тот ещё только писал либретто для опер и начинал набрасывать музыкальные идеи. Вы знакомы с мыслями Фейербаха, даже если не читали ни строчки из его работ. Знаете идею из 1960-х о том, что если молодёжь сбросит бремя прогнившего общества, примет свободную любовь и мир, наступит новый золотой век? Это изобрёл Фейербах.

Людвиг Фейербах. Наденьте на него бусы и рубашку в стиле тай-дай — и он впишется в угол Хейт-Эшбери в 1966.
Поколения моложе моего скорее всего просто рассмеются, если им показать «Эпоху Водолея» из хиппового мюзикла «Волосы» — одну из самых экзальтированных современных интерпретаций этого видения. Я до сих пор помню, как многие искренне верили в подобные идеи. А ведь в 1841 году, когда Фейербах только ввёл эту идею, она ещё не была многократно опровергнута катастрофами, и оттого казалась даже более убедительной. Она впечатлила многих молодых радикалов, включая Вагнера.
Для зрелого же Вагнера, когда он уже работал над музыкой для Кольца, путеводной звездой стала глубоко отличная мысль другого философа — Артура Шопенгауэра. Противоречия между этими двумя философами пронизывает все четыре оперы, и это значимо не только в музыкальном смысле. Фейербах был, среди прочего, политическим философом и оптимистом, верившим всей душой в грядущий прекрасный мир; Шопенгауэр — пессимистом, отвергавшим саму идею, что политические изменения могут изменить человеческую природу. Вопреки клише, Вагнер всю жизнь находился на крайне левом фланге политики (да, мы к этому тоже вернёмся), и десятилетия работы над Кольцом совпали с периодом, когда его собственные политические убеждения подвергались жёсткой проверке жизнью. Поразительно то, как он вплёл в свою музыку и это противоречие, и свою глубокую амбивалентность относительно его разрешения.

Артур Шопенгауэр. Среди прочего, он единственный крупный западный философ, серьёзно относившийся к азиатской философии.
Как результат, в Кольце Вагнер попытался символически изложить всю историю западной цивилизации от рассвета до заката. Каждая опера играет свою роль в этом грандиозном проекте. «Золото Рейна» обозначает основную проблему, используя богов, карликов и великанов германской мифологии как аллегории социальных классов и философских принципов. «Валькирия» и первые две трети «Зигфрида» суммируют всю западную историю до времени Вагнера. Последний акт «Зигфрида» и начало «Гибели богов» изображают современную Вагнеру эпоху, а остаток финальной оперы — пророчество о будущем.
Вам кажется, что перед вами один из тех «притянутых за уши» анализов, которые критики так любят навешивать на произведения? Да, подобные умозаключения можно счесть изощрёнными и напыщенными, но это вовсе не выдумка критика. Сам Вагнер написал целые тома о смысле Кольца. Он изложил всю историю концепции Кольца в трёх полноценных книгах и множестве писем. Будучи Вагнером, он писал постоянно, и его письма всегда касались только его самого, его работы, его идей и… что ж, здесь мы подходим к другой стороне Рихарда Вагнера.

Рихард Вагнер, одинаково исключительный как гений и как мерзавец.
Дело в том, что при всём своём гении он был жалким подобием человека. Он, кажется, родился, чтобы раз и навсегда доказать, что можно одновременно быть величайшим творческим гением и величайшим мерзавцем. Он обладал выдающимся интеллектом, способным уследить за последними тенденциями в фольклористике, философии, политэкономии и музыке, но ни разу не удосужился применить даже крупицу своего ума к собственным разрушительным привычкам, презрительным предрассудкам или чудовищно жестокому обращению со всеми вокруг.
Это был человек, любивший роскошь, которую, однако, не мог себе позволить, пока не нашёл эксцентричного короля, дававшего деньги без вопросов. До этого Вагнер занимал у всех, включая ближайших друзей, а потом бесился, если те вдруг просили вернуть долг. Он делал это так часто и упорно, что ему приходилось годами спасаться от полиции за границей. Другие его поступки было в том же ключе. Если бы вы были другом Вагнера, вам бы приходилось мириться с тем, что всё вертится вокруг него, а на вашу долю уготована лишь роль обожающего почитателя пред алтарём Рихарда Вагнера.

Георг Вильгельм Фридрих Гегель, размышляющий о своей божественности.
Конечно, в то время подобное было даже более распространено среди знаменитостей, чем сейчас. Для европейских интеллектуалов XIX века было обычным делом считать себя и свои идеи поворотным пунктом всей истории. Вагнеру, и впрямь, было далеко до Шарля Фурье, изобретателя социализма, верившего, что океаны превратятся в лимонад, как только все примут его философию. Или до Г.В.Ф. Гегеля, утверждавшего, что в нём Абсолют — божественная сущность всего — впервые обрёл самосознание. И хотя Вагнер и не достиг подобного космического уровня наглости, его эго было тем не менее столь грандиозным, что рядом с ним Дональд Трамп выглядел бы скромником.
И именно поэтому мы точно знаем, какой смысл Вагнер вкладывал в Кольцо. Он был настолько убеждён во всемирной значимости любой его мысли, что документировал буквально всё в письмах, эссе и книгах, дабы ни одно золотое слово не потерялось для потомков. Это рай для биографов и критиков, изучающих контекст. Вам не нужно гадать, что Вагнер думал о чём-либо — он сам всё рассказывал. К ужасу трудившейся над его публичным имиджем жены, и его друзей, он совершенно не умел фильтровать свои слова; когда какая-либо мысль приходила к нему, он высказывал её, обычно в печати и как можно публичнее. Если люди обижались — что ж, для Вагнера это лишь доказывало их неправоту.

Джакомо Мейербер, куда более приятный человек, чем Вагнер. Его оперы больше не ставят — они были популярны, но не так хороши.
Что придавало его более чем гироскопическому эгоцентризму горький привкус, так это озлобленность. Для него его талант был настолько очевиден, а музыка — настолько важна, что он быстро пришёл к выводу: единственная причина, по которой люди не ценили это так же высоко, как он сам, заключалась в заговоре, работавшем денно и нощно, чтобы его принизить. Я уже упоминал, что он был параноиком? Он был параноиком. Поэтому он постоянно нервно поглядывал на окружающих, пытаясь уловить, не проговорятся ли они о чём-то таком, что выдаст их участие в зловещем заговоре против него.
Между прочим, он был яростным антисемитом и столь же яростным франкофобом. Оба этих предрассудка были широко распространены в Германии его эпохи, но Вагнер воспринимал их лично — по причинам, вытекающим из уже упомянутых пунктов. Так сложилось, что в молодости, когда он как композитор пытался пробиться наверх, самым влиятельным оперным композитором мира был Джакомо Мейербер, который, как нарочно, оказался евреем. Кроме того, в то время евреи всё ещё доминировали в ростовщическом бизнесе в большей части Европы. Вот и получился Вагнер: убеждённый в своем подавляющем превосходстве над Мейербером, он объяснял богатство и славу последнего лишь заговором, а тот факт, что ростовщики, у которых он занимал деньги для своей расточительной жизни, требовали возврата долгов, — тем же самым. Слюнявые тирады о «еврейских кознях» следовали за этим как ночь за днём.
Его ненависть к французам имела схожие корни. В молодости он отправился в Париж, будучи уверен, что все мгновенно признают, насколько его оперы превосходят творения других. Думаю, вы можете представить, что парижские композиторы, журналисты и оперные критики подумали об этом. Он так и не простил им того, что они не пали перед ним ниц.
Всё это невозможно игнорировать, говоря о Вагнере. Всё это подробно исследовано в десятках его биографий. Впрочем как следующий вопрос, который нам предстоит затронуть, а именно, что почти через десятилетие после смерти композитора у Вагнера появился один бледнолицый австрийский фанат. Так точно, здесь на сцене появляется Адольф Гитлер.

Никогда не судите об артисте по поведению его фанатов.
Гитлер был одержим Вагнером с самого детства. Согласно Августу Кубицеку, одному из немногих его друзей в юности, именно после просмотра ранней оперы Вагнера «Риенци» Гитлер внезапно заявил, что однажды пойдёт в политику. Ситуацию усугубило то, что, когда Гитлер прошёл путь от неудачливого художника до солдата, политического активиста и, наконец, рейхсканцлера, Винифред Вагнер — англичанка, вдова сына Вагнера Зигфрида — безумно влюбилась в фюрера. Она отчаянно хотела выйти за него замуж. Он так и не сделал ей предложения (это отдельная мутная история), но на протяжении всех двенадцати лет существования рейха Гитлер мог рассчитывать на тёплый приём и раболепное пресмыкательство со стороны семьи Вагнеров и Байрёйтского театра.
В результате многие автоматически полагают, что Вагнер был нацистом, «протонацистом» или как минимум запятнан любовью нацистов к его операм. Au contraire: большинство нацистов не находили времени для оперы — тщетные попытки Гитлера заставить подчинённых посещать Вагнера стали в нацистcкой партии поводом для насмешек. Что же до самого Вагнера, он находился на противоположном конце политического спектра. По меркам своего времени, в молодости он был ярым левым радикалом. В зрелые годы, уже убеждённый своим горьким опытом, он хоть и сохранил левые идеалы, но разуверился в возможности их реализации через политический процесс.

Михаил Бакунин, дружбан Вагнера в контркультуре 1840–х.
Ультралевая радикальность Вагнера была настолько затушевана невежественными комментаторами, что стоит подчеркнуть это особо. Большинство из тех, кто хоть что-то слышал об анархизме, знают о Михаиле Бакунине; для остальных же поясню: он был самым влиятельным теоретиком и активистом анархизма XIX века. Он и Рихард Вагнер были близкими друзьями и сражались бок о бок на баррикадах во время провалившихся европейских революций 1848–1849 годов. Участие Вагнера в одном из этих восстаний было настолько значимым, что после его разгрома Вагнеру пришлось бежать через границу в Швейцарию пряча свою голову от назначенного за неё вознаграждения.
Затруднение в понимании политических взглядов Вагнера современниками связано с тем, что его идеи сформировались под влиянием забытого мира домарксистского социализма. Марксисты тщательно замалчивают этот период, поскольку он предлагает альтернативы мрачному тоталитарному государству, возникающему при воплощении марксизма на практике. Сторонники политико-экономических систем правее марксизма также заинтересованы в забвении этих альтернатив: это позволяет им указывать на чудовищные провалы марксизма, чтобы атаковать левых оппонентов. Удобно для обеих сторон.
Впрочем, это не означает, что домарксистский социализм работает лучше марксистского. Как убедился Вагнер после 1848–1849 годов, а многие из нас — после 1960-х, идеи Фейербаха и других идеологов того движения оказались нежизнеспособными в реальном мире. Однако это две разные нежизнеспособности: домарксистский социализм провалился, потому что он попросту не работал на практике; марксистский социализм провалился, потому что на практике он превращался в серую бюрократическую тиранию, удерживающую власть через лагеря и массовые расстрелы. Оба провала закономерны, и мы ещё вернёмся к этому, особенно потому, что в «Кольце» Вагнер указал на главную слабость знакомого ему радикализма.
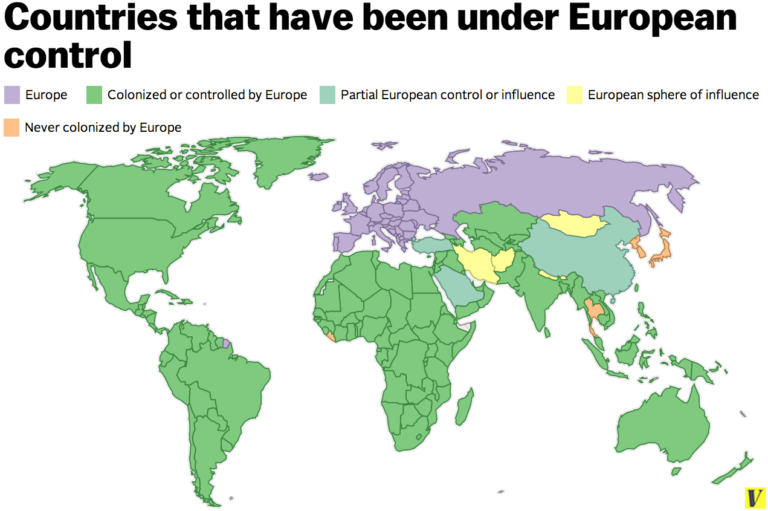
Страны бывавшие под европейским контролем. Да, и мирным этот процесс тоже не был.
Но «Кольцо» — это не только политическая экономия, а Вагнер — не просто грандиозный придурок, который оказался блестящим творцом. В каком-то очень реальном смысле Рихард Вагнер — это тройной перегонки, очищенный угольным фильтром концентрат Европы своей эпохи, зенита европейской глобальной империи — крупнейшей в истории планеты и одной из самых жестоких и хищных. В своем неугомонном творческом гении, поразительных прозрениях во всем, кроме самого себя, фантастической надменности и грубой жестокости по отношению к окружающим, он стал идеальным символом всего европейского проекта. «Кольцо нибелунга», в свою очередь, представляет собой последовательную попытку — наиболее значимую в истории западного искусства — охватить траекторию глобального европейского проекта в целом и спроецировать его в будущее, уже активно формировавшееся в эпоху Вагнера.
Но европейский проект не желал заканчиваться чем-то хорошим. Для того чтобы научиться уживаться с этим Вагнеру понадобились годы. Завершив оперное воплощение прошлого и подступившись к настоящему и будущему, Вагнер едва не отказался от всей задумки. Величественное видение будущего свободных духом и любовью, которое он почерпнул у Фейербаха, Бакунина и бурлящего котла европейской контркультуры, породившей провалившиеся революции 1848–1849 годов, мечта, направлявшая первую половину его жизни, — именно на этом он изначально хотел завершить «Кольцо». Потребовались годы и множество периодов клинической депрессии, когда он неоднократно задумывался о самоубийстве, чтобы его собственная интуиция наконец убедила его: подобное будущее невозможно.

«Парсифаль» в книге Мэнли П. Холла «Тайные учения всех веков». И других опер там тоже не сыскать.
Что касается того, как он представлял себе возможное будущее, об этом мы ещё поговорим. Вопрос усложняется тем фактом, что Вагнер написал ещё и пятую оперу — «Парсифаль», своё последнее и, возможно, лучшее произведение. В ней он подхватил темы «Кольца нибелунга», переосмыслил их в новых формах и завершил всю сагу так, как не мог даже себе представить, когда только начинал работу над «Кольцом». Параллели настолько точны, что можно смело считать «Парсифаль» пятой оперой цикла «Кольцо нибелунга». Но и это мы разберём в своё время.
Впрочем, прежде чем добраться до этого, предстоит многое обсудить. В следующей части мы поговорим о легендах и мифах, которые стали для Вагнера материалом для опер, об исторических событиях, породивших их, и о колоссальном влиянии — как благом, так и губительном — которое эти легенды оказали, вновь всплыв на поверхность в эпоху Вагнера. Следите за новостями.
Оригинал статьи: The Nibelung’s Ring: Prelude
25 May 2019
Исходники по адресу https://github.com/vasily-kartashov/thai-consonants, сама таблица выглядит вот так: